Итак, сегодня мы будем расширять функциональность Круптара.
Многим уже полюбился этот чрезвычайно гибкий инструмент для выдирания,
редактирования и вставки обратно игрового скрипта. И сегодня, дорогой друг, ты
поймёшь, что его возможности действительно безграничны, ибо он позволяет
редактировать и упакованный текст! Конечно, для этого потребуется чуть больше,
чем базовые знания в ромхакинге, но ведь когда-то нужно развиваться. Но обо
всём по порядку.
Для хорошего усвоения нового урока нам понадобятся:
Kruptar 7
Исходники плагинов
под него (нас будет интересовать Null плагин)
Delphi (у меня была 7-я версия) и, разумеется, знание языка.
РОМ жертва: Snake's Revenge (U).nes
Вскрытие пациента.
Для начала нужно поближе познакомиться с нашим сегодняшним гостем: Snake's Revenge.
Про игру много говорить не буду (многие её не жалуют), зато в желающих перевести её дефицита
нет
(насколько я знаю, игра до сих пор полностью не переведена). На самом деле,
основной скрипт здесь не зажат, зато текст, появляющийся в TRCVR (прадедушка
Codec’а), не хочет отыскиваться Relative Search’ем.
Поэтому после непродолжительных манипуляций (содержание которых выходит за
рамки данного документа) находим, наконец, вот такой кусок кода, отвечающий за
распаковку текста в RAM, откуда в дальнейшем он перемещается в память PPU (кто привык копаться в
голых данных эмпирическими методам и методами научного тыка могут сразу переходить к концу данной главы):
ROM:A75A uncomp: ; CODE XREF:
ROM:A7BEj
ROM:A75A LDA byte_41 ;загружаем номер сообщения
ROM:A75C ASL A ;умножаем на два (указатели
двухбайтовые)
ROM:A75D TAY
ROM:A75E LDA PTR_table,Y
ROM:A761 STA Ptr_low
ROM:A763 LDA PTR_table+1,Y
ROM:A766 STA Ptr_high ;Загружаем соответствующий указатель
ROM:A768 LDA byte_42 ;Загружаем смещение от начала
сообщения
ROM:A76A BNE loc_A76F ;В начале здесь всегда ноль.
ROM:A76C STA Offset
ROM:A76F
ROM:A76F loc_A76F: ; CODE XREF: ROM:A76Aj
ROM:A76F LDY Offset
ROM:A772 LDX #0
ROM:A774 LDA (Ptr_low),Y ;Загружаем байт из упакованного потока
ROM:A776
ROM:A776 loc_A776: ; CODE XREF: ROM:loc_A7B1j
ROM:A776 LSR A
ROM:A777 LSR A
ROM:A778 STA Unpacked_char_Buffer,X;
сохранение в поток распакованного
ROM:A77B INX ; текста
ROM:A77C CPX #$40 ; '@' ;в сообщении не больше $40 символов
ROM:A77E BEQ loc_A784
ROM:A780 CMP #$3F ; '?' ; $3F- конец распаковки
ROM:A782 BNE Index_Operation
ROM:A784
ROM:A784 loc_A784: ; CODE XREF: ROM:A77Ej
ROM:A784 STY Offset
ROM:A787 JMP loc_A7C0
ROM:A78A ;
---------------------------------------------------------------------------
ROM:A78A
ROM:A78A Index_Operation: ; CODE XREF: ROM:A782j
ROM:A78A TXA
ROM:A78B LSR A ; Хитрая процедура, чтобы в случае,
если из
ROM:A78B ; предыдущего
байта в последующий перекидывается 6
ROM:A78B ; бит, да еще от двух младших избавляемя, чтобы этот
ROM:A78B ; последующий байт не
пропал - в итоге при X=3
ROM:A78B
; Y не
изменится
ROM:A78C LSR A
ROM:A78D STA byte_7
ROM:A78F TXA
ROM:A790 CLC
ROM:A791 SBC byte_7
ROM:A793 CLC
ROM:A794 ADC Offset
ROM:A797 TAY
ROM:A798 TXA
ROM:A799 AND #3
ROM:A79B STA Counter
ROM:A79D LDA (Ptr_low),Y ;Загружаем байт из упакованного потока
ROM:A79F STA First_Byte
ROM:A7A1 INY
ROM:A7A2 LDA (Ptr_low),Y
;Загружаем байт из упакованного потока
ROM:A7A4
ROM:A7A4 TwoBits_InSecondByte: ; CODE XREF:
ROM:A7AEj
ROM:A7A4 DEC Counter
ROM:A7A6 BMI loc_A7B1
ROM:A7A8 LSR First_Byte ; Два младших бита первого байта
переходят
ROM:A7A8 ; в два старших второго, причем два
младших
ROM:A7A8 ; бита второго уже не используются
ROM:A7AA ROR A
ROM:A7AB LSR First_Byte
ROM:A7AD ROR A
ROM:A7AE
JMP TwoBits_InSecondByte
ROM:A7B1 ;
---------------------------------------------------------------------------
ROM:A7B1
ROM:A7B1 loc_A7B1: ; CODE XREF: ROM:A7A6j
ROM:A7B1 JMP loc_A776 ; дальнейшая обработка распакованного текста
|
Испугался? Думаю, в графическом представлении все выглядит
не так страшно:
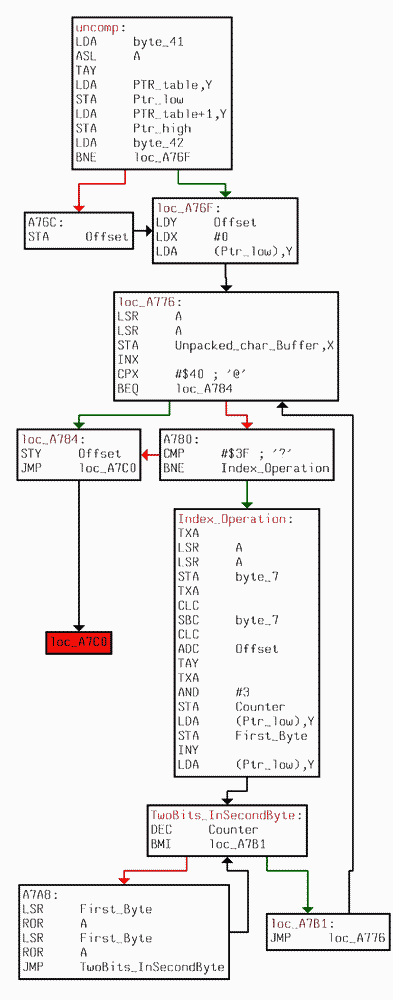
Если кто ещё не догадался, то это банальная шестибитная кодировка одного символа.
То есть в индексе каждого символа используется не 8 бит (целый байт), а всего 6 (два старших не используются).
Легко подсчитать, что двоичное 00111111 – даёт нам максимально возможных 64 используемых символа (а нам
больше и не надо). Таким образом, имеем входной битовый поток, в котором, например, в первом байте будут
6 бит первого символа и ещё два бита от второго символа, во втором байте – уже четыре бита второго символа
и четыре бита третьего символа и так далее. Разумеется, relative search не мог обнаружить текст, упакованный
таким образом.
По старинке.
Ну, как водится, можно было бы написать простенькую программку, которая бы читала входной поток и выдавала
в выходной индексы символов (практически готовый скрипт, только его ещё надо прогнать через таблицу). Для
подтверждения эмпирических данных, полученных из анализа кода игры. Так и сделаем:
Sinput :=Tmemorystream.Create; //Входной файл
Soutput := Tmemorystream.Create; //Выходной файл
Sinput.Position := Offset; //Оffset – смещение начала упакованного сообщения
Sinput.LoadFromFile(Filename);
Bit := 0;//Временная переменная, которая будет носить в себе один бит
SI := 0;//Счетчик бит входного потока
DI := 0;//Счетчик бит выходного потока
DB := 0;// Destination_Byte - Байт выходного потока
count := 0;// Счетчик сколько нам нужно распаковать байт
Sinput.Read(SB,1);// Source_Byte - SB – байт входного потока
While Count < $30 do //для контроля распакуем 48 символов
Begin
Bit := (SB and $80) shr 7;//берём старший бит входного байта
SB := SB shl 1;
inc (SI);
If SI = 8 Then
Begin //Если байт входного потока
исчерпан, читаем новый
SI :=0;
SInput.Read(SB,1);
end;
DB := DB shl 1;
DB:= DB or
Bit; //Записываем наш бит в младший бит выходного потока
inc (DI);
If DI = 6
then
Begin //Если байт выходного потока
исчерпан, сохраняем его в выходной поток.
DI:=0;
SOutput.Write(DB,1);
DB :=0;
inc (Count);
end;
end;
SOutput.SaveToFile('Out.bin');
Sinput.free;
Soutput.Free;
|
Думаю, излишне говорить, что распакованный файл по своему содержимому должен совпадать с текстовой частью
тайловой карты, когда в неё выводится игровой текст, которую можно увидеть в Name Table Viewer в FCEUXD,
плюс байты конца строки и конца сообщения (вот заодно и узнаем их значения и сможем окончательно составить таблицу).
Кстати о значениях байтов: что ещё мы можем узнать из кода игры? Ну, начнём со стандартной процедуры: составление
таблицы (мою можно найти в
проекте Круптара,
распаковав его как .zip архив). Обратили внимание на строки:
3B=
3C="
Откуда я узнал? Да вот отсюда:
ROM:A7C5 LDA Unpacked_char_Buffer,Y
ROM:A7C8 CMP #$3B ; ';'
ROM:A7CA BEQ loc_A7FD ; процедура подмены индекса на пробел
ROM:A7CC CMP #$3C ; '<'
ROM:A7CE BNE loc_A7FF
ROM:A7D0 LDA #$75 ; в Pattern Table это индекс значка "
ROM:A7D2 BNE loc_A7FF
|
Строки типа:
3D
3E
ends
3F
специфичны для Круптара и означают, что $3D и $3E – байты разрыва строки, а $3F – байт конца строки.
И, наконец, финальный аккорд: когда я осматривал таблицу указателей (она есть в коде – я её переименовал в
PTR_table), то обнаружил, что она расположена прямо перед блоками с текстом, но между старшим байтом последнего
указателя и местом, на которое указывает первый указатель, стоит один непонятный байт! Можете убедиться сами,
открыв РОМ по смещению 0хEA88 – перед ним стоит указатель на последний текстовый блок (имеет значение $B0A3,
затем идёт неизвестный байт $03, затем (по смещению 0xEA89) первый байт упакованного потока текста, на который
ссылается первый указатель таблицы со значением $AA79). Экспериментально распаковав несколько байт второго
текстового блока своей тестовой программкой, и дойдя до этого текста в игре (это брифинг пилота о том, что нужно
проникнуть в логово врага и собрать информацию – сразу после прохождения первого экрана), поменяем этот байт,
скажем, на ноль, единичку и т.п. и выясним, что этот байт отвечает за то, кто именно говорит в этот момент по
TRCVR (волосатый мужик, негр, девушка, пилот…). Назовём его байтом атрибута текста. С ним придётся считаться:
скорее всего, он расположен перед каждым текстовым блоком (я уже показал, что он есть перед первым и вторым),
поэтому, когда мы станем работать с полным скриптом игры, нам придётся вынимать и вставлять обратно этот байт
атрибута неупакованным (небольшое затруднение, с которым Круптар с честью справится). Даже, несмотря на то, что
указатель-то ссылается как раз на текстовый блок за байтом атрибута, а не на сам атрибут:
$A645:B9 3E AA LDA $AA3E,Y @ $AA40 = #$B4; Загрузка младшего байта указателя на второй текстовый блок. (в $AA3E таблица указателей)
$A648:38 SEC
$A649:E9 01 SBC #$01 ;Отнимаем единичку! Теперь будет загружаться байт, стоящий перед вторым текстовым блоком
$A64B:85 10 STA $0010 = #$00
$A64D:B9 3F AA LDA $AA3F,Y @ $AA41 = #$AA; Загрузка старшего байта указателя на второй текстовый блок
$A650:E9 00 SBC #$00
$A652:85 11 STA $0011 = #$A2
$A654:A0 00 LDY #$00
$A656:B1 10 LDA ($10),Y @ $AAB3 = #$03 ;Непосредственно загрузка байта атрибута.
|
Великолепно! Мы узнали всё, что нам нужно и ассемблерная часть на этом закончена.
Что теперь? Ну, в былые времена, я бы посоветовал вам прикрутить к тестовой программке поддержку таблиц
(что само по себе уже нетривиальная задача), затем поддержку использования и изменения указателей, сохранять
всё это в текстовый файл и молиться каждый раз как вставляете текст, чтобы получившийся упакованный скрипт не
налез на какие-нибудь жизненно важные для игры данные или делать проверку на размер получившегося выходного
потока, что также не прибавляет программе легковесности.
Но мы живём в новой эре, дружище. Поэтому для всех этих рутинных процедур можно использовать Круптар, а
получившийся проект будет являться компактным файликом, который содержит скрипт правильно отформатированный
по переносам строк, с возможностью поиска и тому подобными милыми вещами. Более того, поддержка пойнтеров
добавится почти автоматически! А работать переводчику в таком проекте просто одно удовольствие: не укладываешься
в рамки отведённого пространства – Круптар деликатно напомнит об этом. В общем, ромхакер делает то, что ему
действительно нравится – остаётся один на один только с процедурой упаковки/распаковки данных – все побочные
телодвижения (типа вынимания скрипта, работы с таблицами и пойнтерами) производятся в Круптаре за пару минут.
Новая эра.
Итак, приступим к делу: наша задача написать плагин к Круптару, который распаковывал бы входной поток,
представлял всё это в понятном для Круптаре виде, а затем, после перевода делал бы всё наоборот.
Несколько слов о плагинах: на самом деле исходный текст плагина – это простой проект в Дельфи с расширением .dpr
и после компиляции будет представлять собой динамическую библиотеку, вроде тех, что использует система (.dll),
только с расширением .kpl. С нашими исходными файлами можно работать как с простым проектом Дельфи, то есть
существует возможность запускать приложение для отладки (только для этого необходимо указать Круптар, как Host
приложение (Run ->Parameters… ->Local ->Host Application)). Компилировать же плагин можно и без Круптара. Стоит
также отметить, что Круптар всегда использует плагины. И даже, когда мы вытаскиваем неупакованный скрипт, в
Круптар загружен плагин «Standard.kpl».
Писать свой плагин, разумеется, мы будем не с чистого листа. Печка, от которой будем плясать – «Null», то есть
пустой плагин (плагин для извлечения строк стандартного формата PChar - то есть с ноликом в конце строки).
Итак, откроем Null.dpr и внимательно изучим. Сразу переименуем его (мой называется SR.dpr) Попутно можно будет
поменять имя и описание плагина (KPLDescription) с Null на что-нибудь более содержательное (этот текст будет
отображаться в окне Справка -> Библиотеки). Пока что нас интересует только распаковка (о запаковке можно
позаботиться потом – пока что просто достанем наш скрипт в читаемом виде).
Распаковка.
После подключения к проекту Круптара нашего плагина весь входной поток скрипта будет проходить через функцию
«GetStrings», за один проход которой будет обработано одно сообщение (или в общем случае, блок, на который
ссылается указатель, введённый в проект Круптара):
Function GetStrings(X, Sz: Integer): PTextStrings; stdcall; // X - Смещение текстовых данных в роме
// Sz - размер строки, указанный в ptStringLength (его можно
//не использовать в своих плагинах)
Var P: PChar; // null-terminated string
begin
Result := NIL;
If (X >= RomSize) or (X < 0) then Exit; // RomSize – размер загруженного в проект РОМа
New(Result, Init); //Интциализация
With Result^.Add^ do
begin
P := Addr(ROM^[X]); // ROM: Pbytes – типизированный указатель на данные РОМа
Str := '';
While P^ <> #0 do //Если встретили ноль, значит строка закончена
begin
Str := Str + P^; //Копируем данные в строку
Inc(P);
end;
end;
end;
|
Тут ничего не скажешь: Djinn в первую очередь заботился об эффективности и быстродействии, а не о наглядности
кода. Хотя, вся нужная нам информация может быть найдена в исходниках плагина (в т.ч. см. Needs.pas), всё же
поясним тип возвращаемого функцией результата – PtextStrings:
PTextStrings = ^ TTextStrings; // PTextStrings - это динамический массив состоящий из PTextString
TTextStrings = Object
Root, Cur: PTextString;// Root - указатель на первый элемент массива
Count: Integer; // количество элементов в массиве
Constructor Init; //подробно см. Needs.pas
Function Add: PTextString;
Function Get(I: Integer): PTextString;
Destructor Done;
end;
|
где PTextString:
PTextString = ^TTextString;
TTextString = Record
Str: String;
Next: PTextString;
end;
|
В функции GetStrings и будет происходить наша распаковка. Вот один из вариантов реализации этого (код учебный,
поэтому в нём даже есть лишние переменные, добавленные для наглядности):
Function GetStrings(X, Sz: Integer): PTextStrings; stdcall;
Var B, SI, DI, DB, Bit: byte; //Переменные, как и в моей тестовой программе
begin
Result := NIL;
Bit:=0;
SI:=0;
DI:=0;
DB :=0;
If (X >= RomSize) or (X < 0) then Exit;
New(Result, Init);
With Result^.Add^ do
begin //Легко узнать в дальнейших строках мою тестовую программу
Str:='';
Str := Str + Char(ROM^[X]); // первый байт не распаковываем - атрибут.
inc (x);
B := ROM^[X];
Repeat //бесконечный цикл, выход из которого возможен только по Break
Bit := (B and $80) shr 7; //берём старший бит входного байта
B := B shl 1;
inc (SI);
If SI = 8 Then
Begin //Если байт входного потока исчерпан, читаем новый
SI :=0;
inc(X);
B := ROM^[X];
end;
DB := DB shl 1;
DB:= DB or
Bit; //Записываем наш бит в младший бит выходного потока
inc (DI);
If DI = 6 then
Begin //Если байт выходного потока исчерпан, сохраняем его в выходной поток.
DI:=0;
if DB = $3F then
begin //Если распакован символ конца сообщения, сохраняем его в выходной поток и выходим.
Str := Str + Char(DB);
break ;
end
else
Str := Str + Char(DB);
DB :=0;
end;
Until False;
end;
end;
|
Компилируем наш .dpr c изменённой функцией GetStrings и получаем файл с расширением .kpl, который нужно
поместить в папку Lib, расположенную в корневом каталоге Круптара.
Проект.
Пришло время создать непосредственно проект, с которым сможет работать переводчик. Открываем Круптар,
жмём Ctrl+N и в первую очередь вводим имена оригинального и переведённого РОМов (разумеется, пока что это
два одинаковых файла). В моём случае это соответственно ‘Snake's Revenge (U).nes’ и ‘Snake's Revenge (Rus).nes’
(на случай, если вы будете открывать мой проект). Далее жмём Ctrl+T и добавляем таблицу из файла (или сразу
жмём Ctrl+Alt+T), хотя можно составить таблицу прямо в проекте. Убедитесь, что Круптар правильно воспринял байты
окончания и разрыва строк и не выдал предупреждения по загруженной таблице. Теперь жмём Ctrl+G и добавляем
группу. Тут же указываем в графе grLibrary наш плагин из выпадающего списка (мой называется SR.kpl).
grIsDictionary оставляем false. Далее добавляем блоки для текста – это место в РОМе, которое Круптар будет
использовать для вставки обратно переведённого скрипта. Ну, начало-то мы знаем где: исходя из значения первого
указателя в таблице и учтя, что перед первым текстовым блоком есть ещё один байт атрибута, начало будет по
смещению 0хEA88. А конец где? Пока что это не так важно – пока что мы и не вставляем-то толком скрипт. Укажем
это место наобум и можно с запасом: 0xFFFF. Затем выбираем пойнтеры, и «добавить элемент». Здесь опций уже
больше.
В итоге у вас должно получиться что-то вроде этого:
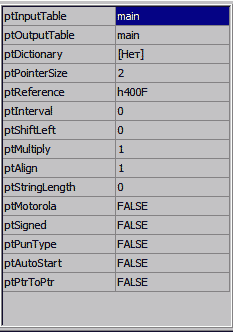
Здесь я менял только поля используемых таблиц, ptPointeSize и ptReference. Далее я расскажу, что означает каждая
графа, а те, кому не интересны все возможности Круптара, могут смело переходить к чтению последнего абзаца этой
части.
-
ptInput/OutputTable – это таблицы, по которым будет производиться, соответственно, вынимание и
вставка скрипта (в моём случае, эти таблицы одинаковые, так как я еще не перерисовывал шрифт и не знаю кодов
будущих русских букв).
-
ptDirctionary указывается группа-словарь, это применяется при работе DTE/MTE скриптами. Группа
становится словарём, если grIsDictionary = TRUE, и становятся активны опции:
Параметры словаря;
Генерировать словарь;
Словарь в таблицу;
Опция "Генерировать словарь" берёт все списки, в которых указан словарь в ptDictionary и генерирует по тексту
словарь, все слова заносятся в эту группу по порядку. Но работает эта опция не очень эффективно.
Борьба с DTE/MTE при помощи Круптара выходит за рамки этого документа, но те, кто заинтересовался этой темой,
могут ознакомиться с
проектом под
Beetlejuice на NES, где для основного скрипта применяется MTE.
-
ptPointerSize – размер указателей в байтах (на NES двухбайтовые указатели). Здесь может быть и ноль.
Например, в некоторых играх указателей на отдельные строки нет вообще (какие адреса писать при добавлении
блока пойнтеров см. объяснение ptStringLength далее).
-
ptReference – очень важный параметр, связанный с особенностью работы Круптара. Объясню подробнее: как
только вы укажете Круптару смещение указателя, он считает его в соответствии с заданным форматом (ptPointerSize,
ptMotorola и т.п.), затем прибавит к значению данного указателя величину ptReference и получит смещение первого
байта входного текстового блока. Как видите, в моём случае, это h400F. Как уже много раз было сказано, первый
байт упакованного текстового блока расположен по смещению 0хEA89, а значение первого указателя: $AA79 (первый
указатель расположен по смещению 0xEA4E). Таким образом, hEA89-hAA79 = h4010. Не забудем про байт атрибута: ведь
указатель ссылается на текстовый блок, а не на него: придётся отнять ещё единичку, чтобы наш атрибут вошёл в
скрипт. Итого получаем h400F. Проверяем: если мы скормим Круптару указатель по смещению 0xEA4E, он прочитает его
как величину $AA79, затем прибавит к ней полученное только что нами h400F и начнёт читать из РОМа байт по
смещению 0хEA88 – то, что надо, это же наш первый байт атрибута ($03)!
-
ptInterval – промежуток в байтах между отдельными указателями (у нас указатели хранятся в монолитном
едином блоке).
-
ptShiftLeft - [исходный пойнтер] shl [значение в этом поле]. Часто формат указателей в игре такой, что
для их использования приходится производить сдвиг байта влево, причем иногда не один раз.
-
ptMultiply – очень часто при вставке скрипта обратно необходимо, чтобы начало строк было кратно по
адресу какому-либо числу, которое и указывается в этом поле (например, на GBA некоторые инструкции правильно
считывают данные только кратные четырём: ldr r0,[r1] – здесь адрес в r1 должен быть кратен 4 обязательно). Это
связано с особенностями железа. И если предположить, что у нас GBA проект и наша строка может начаться, скажем,
с адреса: 0х1АB4A1, то Круптар забивает 1AB4A1,1AB4A2,1AB4A3 нулями, а потом вставляет наш текст в 1AB4A4,
соответственно корректируя указатели на эту строку.
-
ptStringLength – указывается длина в байтах каждой строки. Фиксированная длина строки встречается во
многих играх. Если ptPointerSize равен нулю, а ptStringLength не равен нулю, то при добавлении блока пойнтеров
нужно вписывать адреса первой и последней строк. Если же ptPointerSize и ptStringLength будут равны нулю, то
вписываем адреса первого и последнего байтов текстового блока (внутри блока Круптар будет ориентироваться по
знаку окончания строки). И, как обычно, если ptPointerSize не равен нулю, то вписываем адреса первого и
последнего указателей.
-
ptMotorola – способ хранения указателей: в случае NES младший байт указателя хранится перед старшим,
в процессорах Motorola – наоборот.
-
ptSigned – указатели, которые могут иметь положительное и отрицательное значение (т.е. адресуют вперёд
и назад от своей позиции) иногда применяются в играх на SEGA. Как правило, в РОМе стоит блок с текстом, а после
него пойнтер, указывающий назад на нужную строку (скажем, имеем указатель со значением «-34»; Круптар берет
адрес пойнтера, потом читает его значение, отсчитывает 34 байта назад и считывает эту строку). Если указатели
двухбайтные, то они могут принимать значения от -32768 до +32767. Указатели, имеющие положительные значение,
естественно, адресуют вперёд. Ещё одна особенность ptSigned: ptReference в этом случае уже можно не вписывать,
так как адресация будет происходить от смещения в РОМе указателя.
ptPunType - такой тип используется в игре The Punisher (NES), от того и название "PunType". А смысл
здесь в том, что указатель сам по себе разделён некоторым количеством байт, которое в свою очередь указывается в
ptInterval. Скажем, это мне очень пригодилось при переводе BEE-52, где почти все указатели хранятся в операндах
ассемблерных команд:
…
LDX #$B4; младший байт указателя
LDY #$82; старший байт указателя
…
|
Если кто не знаком с ассемблером 6502, то в хексредакторе мы этот код увидим в виде:
$A2 $B4 $A0 $82 – как видим, между старшим и младшим байтами указателя стоит не интересующий нас байт. Вот тут
мы выставляем в поле ptPunType true, а в графе ptInterval пишем 2. Почему не 1? Это дань совместимости проекта
с предыдущими версиями Круптара. В случае если ptPunType = true, в графу ptInterval вписывается
«значение = количество_байт_в_разрыве +1». Подчеркну, что это не распространяется на случай, когда у нас есть
интервал между самими указателями (prPunType = false).
-
ptAutoStart – если значение этого поля true, то значение поля ptReference становится равным смещению в
РОМе первого указателя в таблице (ptReference уже не заполняем), и к значению каждого указателя в этой таблице
прибавляется ptReference, чтобы получить адрес строки (значение каждого указателя в этом случае есть смещение от
начала таблицы до первого байта строки, на которую ссылается этот указатель).
-
ptPtrToPtr – эта опция применяется в случае, если указатель ссылается на ещё один указатель, который в
свою очередь ссылается на строку текста.
Упаковка.
С тем плагином, что мы написали, пытаться вставить скрипт обратно не имеет никакого смысла – игра его не
воспримет (может быть, даже не влезет в отведенное место, которое мы и так взяли с запасом). После
подключения к проекту Круптара нашего плагина весь выходной поток, возвращаемый в РОМ, будет проходить через
функцию «GetData», за один проход которой будет обработано одно сообщение (или в общем случае, блок, на который
ссылается указатель, введённый в проект Круптара):
Function GetData(TextStrings: PTextStrings): String; stdcall; //Все типы переменных описаны при разборе GetString
Var R: PTextString;// Методы этого класса (см. Needs.pas):
// Add - добавляет новый элемент
// Root - возвращает пойнтер на первый элемент
// Cur – возвращает пойнтер на текущий добавленный - то есть на последний
begin
Result := '';
If TextStrings = NIL then Exit; //Если строк нет, выходим
With TextStrings^ do
begin
R := Root; // R - первый элемент массива
While R <> NIL do
begin
Result := Result + R^.Str + #0; //Возвращаем null-terminted string
R := R^.Next; // R= следующий элемент массива
end;
end;
end;
|
Думаю, пояснять что-либо излишне: по уже сложившемуся алгоритму модифицируем эту функцию следующим образом:
Function GetData(TextStrings: PTextStrings):
String; stdcall;
Var
R: PTextString;
I: integer; // Счётчик прочитанных букв для контроля не вышли ли
мы за границы сообщения.
Bit, DB, DI, SB, SI: byte; // Полная аналогия с
предыдущими функциями
begin
Result := '';
DB:=0;
SB:=0;
DI:=0;
SI := 0;
Bit:=0;
I := 1;
If TextStrings = NIL then Exit;
With TextStrings^ do
begin
R := Root;
With R^ do
Result := Result + Char(Str[I]); //1-ый байт не упаковываем - атрибут.
While R
<> NIL do
begin
//-------------------------Моя процедура--------------------
With R^ do begin
inc(I);
SB := Byte(Str[I]);
SB := SB shl 2; //Старшие два бита кода буквы не используются.
Repeat //бесконечный цикл, выход из которого возможен только по Break.
Bit := (SB and $80) shr 7; //берём старший бит кода буквы.
SB := SB shl 1;
inc (SI);
If SI = 6 then
begin
//Кончился текущий
байт.
inc (I);
if I >
Length(Str) then
Begin //Кончился весь входной поток.
DB := DB or Bit; //(закидываем в выходной (упакованный) поток последний бит
Result := Result + Char(DB shl (7-DI));//и добиваем нулями последний байт выходного потока).
break;
end;
SB := Byte(Str[I]); //Читаем код очередной буквы из скрипта Круптара.
SB := SB shl 2;
//Старшие два бита кода буквы не используются.
SI:=0;
end;
DB := DB or Bit; //Записываем наш бит в младший бит выходного потока.
If DI = 7 then
begin //Если байт выходного потока записан полностью, сохраняем его.
DI :=0;
Result := Result + Char(DB);
DB := 0;
end
else
begin //Если записан не полностю, продолжаем процедуру упаковки.
DB := DB shl 1;
inc (DI);
end;
until false
end; //для with
//------------------------Конец моей процедуры----------------
R := R^.Next;
end;
end;
end;
|
Получилось несколько больше, чем функция распаковки, зато теперь мы сможем смело вставлять скрипт назад.
Компилируем получившийся плагин (уже с двумя модифицированными функциями) и заменяем им тот, который был раньше
в папке Lib (имя плагину менять не стоит – в проекте Круптара уже прописано старое, а прописать новый плагин
возможно только, если все группы проект пусты). Снова открываем наш проект в Круптаре и на этот раз смело жмём
Ctrl+F9, пока не изменяя содержимого скрипта.
Как проверить – всё ли правильно мы упаковали? Теоретически, оригинальный РОМ и тот, куда мы только что
вставили скрипт, должны быть абсолютно одинаковыми. Нам нужно будет сравнить по содержимому эти два файла.
Я пользуюсь Сравнением по Содержимому в Total Commander: выделяем оба РОМа и жмём Shift+F1. Что за чёрт?! Почему
появились различия? Без паники. В первую очередь, становится ясно, что различия есть и в таблицах указателей и
во вставленных текстовых блоках, но различия эти явно сформированы в блоки – это видно невооружённым глазом. А
произошло следующее. В оригинальной игре структура указателей и текстовых блоков была схематично такой:
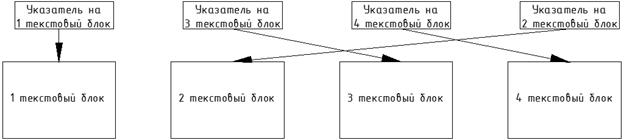
В этом легко убедиться: величины указателей в таблице не всегда возрастают (оставим топорную работу с текстом на
совести разработчиков). Круптар вынимает скрипт из РОМа, естественно, по указателям: текстовые блоки в проекте
идут по порядку появления указателей в таблице (то есть с точки зрения проекта Круптара сначала идёт 1, потом 3,
4 и 2 текстовые блоки), а вот вставляет он скрипт обратно, ориентируясь уже только на текстовые блоки (что
логично, ведь после перевода они могли измениться в размерах), а уже потом корректирует указатели под полученную
структуру блоков:
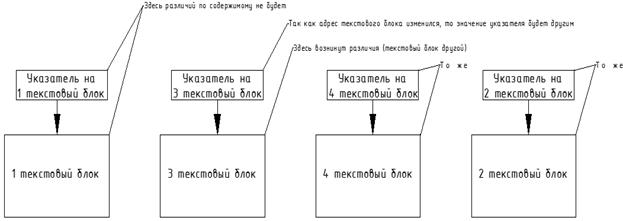
Вот что мы имеем в выходном файле, но с точки зрения игры ничего не изменилось: скажем, номер сообщения равен
двум: как в оригинальном случае, так и после обработки скрипта Круптаром, игра загружает второй по счету
указатель (на третий текстовый блок) и начинает читать из третьего текстового блока. Поэтому мы не только не
навредили, но даже привели в порядок блоки сообщений в игре! Все эти теоретические догадки подтверждаются
элементарным тестированием. Вот первый самовольно перемещённый Круптаром текстовый блок (в скрипте он шестой по
счёту):
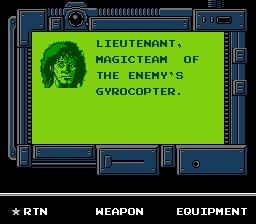
Всё работает правильно и появляется в нужном месте. Как видите, я даже немного поменял текст, чтобы убедиться в
правильности упаковки.
Остался у нас один должок – это я про то, что мы не знали где конец последнего упакованного блока, а значит, не
могли точно определить границы блоков для текста, помнишь? Самое время сделать это. Дело в том, что Круптар
после упаковки текста в указанное нами место («блоки для текста») заполняет оставшиеся до конца
зарезервированного блока байты нулями. Соответственно, так как пакует наш плагин точно так же, как и игра,
начало большого блока с нулями в изменённом РОМе будет свидетельствовать о конце упакованного текста. В
инструменте сравнения по содержимому нужно отыскать нули в изменённом РОМе и посмотреть, где они начинаются: в
нашем случае это смещение 0xF0DC (кстати, сразу после него начинается блок с какими-то указателями). В проекте
вбиваем этот адрес как конечный (не забываем восстановить переводимый РОМ – он уже запорот), и получаем
абсолютно корректный скрипт, с которым можно спокойно работать переводчику.
Конечно, с непривычки может показаться, что всё это дело очень сложное. Однако поверьте мне на слово: без всего
этого можно провозиться раз в пять дольше. Помнится, когда я писал всё по старинке – распаковщик вышел через три
дня, а упаковщик – ещё дня через два (я, правда, до сих пор не могу понять, как он работал). На написание всего
этого документа, вместе с изучением алгоритма и вознёй с картинками у меня ушёл ровно один день.
The End














